
Anyone who has worked around the fields of reliability or quality has certainly bumped into “standard deviation” – a statistic that measures the dispersion within a group of data.
When performing process capability analysis for instance, it’s common practice to randomly draw samples from a population of parts, measure the characteristic of interest on each sample, and then calculate the sample standard deviation using the following formula:
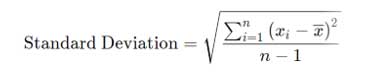
In this formula, xi is the individual measured value, is the arithmetic mean of the individual values, and n is the number of samples drawn. The beauty of this statistic is 1) its versatility, as it is used in a host of other equations, and 2) its resulting popularity. Students of statistics learn the usefulness of this gem early on in their studies.
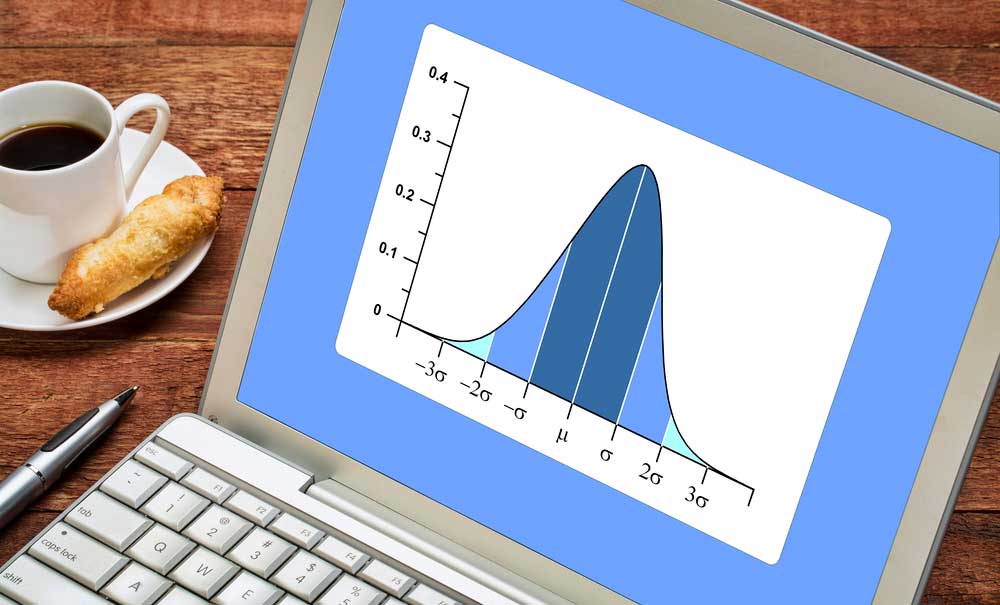
A quality engineer performing process capability analysis on normally distributed data recognizes that 3 standard deviations above and below the arithmetic mean represents the so called “Process Range”, about 99.7 percent of the expected values in the population. For instance, if the arithmetic mean of a 30-piece sample drawn from a 1,000-piece population equals 10.0 and its standard deviation equals 1.0, then the process range equals a total of 6.0, from 7.0 to 13.0.
It’s at this point where understanding Standard Error is important. Standard Error is “a measure of the statistical accuracy of an estimate, equal to the standard deviation of the theoretical distribution of a large population of such estimates.”1 Yes, that’s a mouthful. But let’s reconsider our process capability analysis example as a means of understanding this important statistic.
Imagine the same quality engineer drew a new set of 30 pieces from the same population of 1,000 pieces, and measured the same characteristic using the same measurement equipment. When they calculate the new arithmetic mean and standard deviation, do you think they will get the exact same values as the first set of 30 pieces? No, they will almost certainly obtain slightly different values. After all, these are estimates of the true population parameters based on a much smaller sample. If we wanted to know the true value for the arithmetic mean and standard deviation of the population, then we would need to measure all 1,000 pieces.
If the engineer repeatedly sampled 30 new pieces, each time they would get slightly different estimates for these same values. The standard error therefore is the standard deviation of these estimates.
So the payoff of using a 30-piece sample to estimate the arithmetic mean (or any other statistic) of the 1,000 piece population is that you can get a pretty good estimate of the true arithmetic mean without the work of measuring all 1,000 pieces. Sounds like a good deal. But the question is: How good is our estimate? The standard error of the mean (or of any statistic in question) answers that question.
Logically it follows that as our sample size approaches our population size the accuracy of our estimate of the arithmetic mean gets increasingly better since fewer and fewer pieces get left out of the sample. In other words, the accuracy of our estimate is a function of our sample size. The formula for the standard error of the mean (sometime abbreviated “SEM”) is:
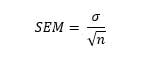
In this formula, σ equals the sample standard deviation and n equals the sample size.
Let’s revisit our process capability analysis example one last time. With a sample standard deviation of 1.0 and a sample size of 30, our SEM equals .183. Since SEM is the standard deviation of the distribution of our sample means, we could infer that 99.7% of all of our estimates of the sample mean, based on repeatedly pulling 30-piece samples, will fall within +/- 3 SEM’s of our arithmetic mean of 10.0.
Across a wide range of fields of study, scientists and engineers more commonly cite either a 90% or 95% confidence interval for their estimates. Translating the confidence interval of your choice to the appropriate number of SEM’s from the mean can be done using a statistical function within Excel or with a Z-score table.
For a deep dive into all things related to Process Capability Analysis, check out my class on Udemy.com by following this link: https://www.udemy.com/course/process-capability-analysis/?referralCode=3604CE93C304A82A0F9F
1. https://www.lexico.com/definition/standard_error